BEST Office TOF Sensor Activity

- 1.
 TU Wien
TU Wien
Description
Abstract
This experiment involves training a machine learning model to predict door activity levels from sensor readings, based on time features. A TOF sensor mounted near a doorway collected distance measurements, which were filtered, aggregated, and labelled as activity counts in 10-minute bins. These were then used as training targets for a gradient boosting model. The model’s predictions were evaluated against a holdout test set and visualised in a time series plot. The goal of the project was to demonstrate basic principles of reproducible modelling and data publication, including FAIR metadata.
Context and methodology
This upload is part of a coursework project in the Data Stewardship course, TU Wien, 2025 summer semester. The model and results were generated for the assignment.
The dataset used consists of distance measurements captured by a TOF sensor installed near a door in the BEST Office (Room Code ACEG38). The data was cleaned, filtered and aggregated into 10-minute activity intervals. The machine learning pipeline was implemented in Python and includes preprocessing, model training, and evaluation stages. A gradient-boosted regression model was trained to predict activity counts based on time-based features (hour, minute, day of week, and weekend).
Technical details
Language and environment: Python 3.12, using scikit-learn, pandas, matplotlib
Model type:
HistGradientBoostingRegressorfrom scikit-learn, trained using Poisson lossOutput files:
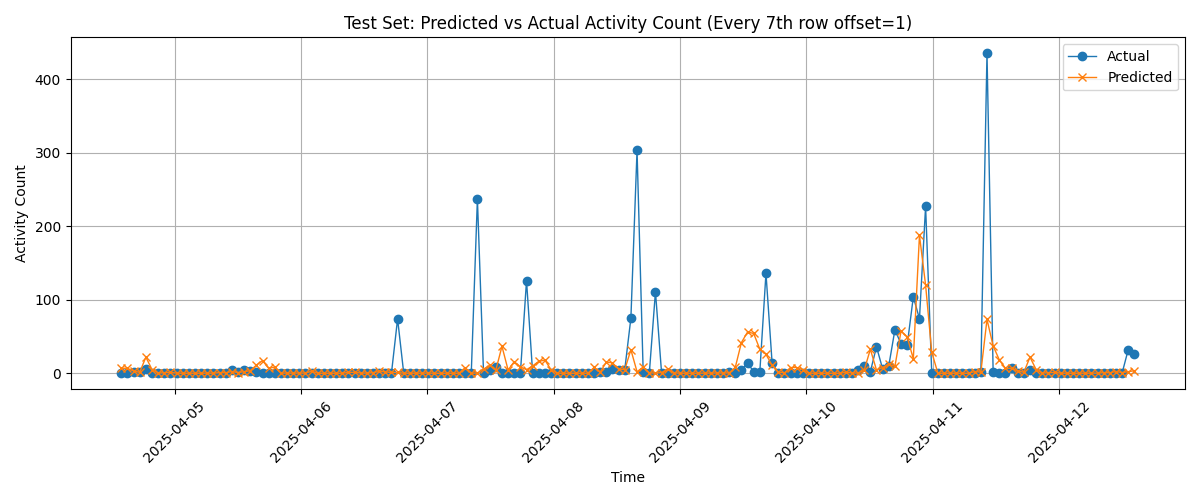
output_model.pkl: The trained machine learning model (serialised usingjoblib)test_predictions_plot.png: A visual comparison of predicted vs. actual activity counts for the test set
The plot illustrates model performance using the test partition of the dataset, showing how well the predicted activity matches actual observations over time.
Provenance and metadata
Creator: Raphael-Hafis Kretschmer, TU Wien
Year: 2025
Language: Python
Dependencies: scikit-learn, matplotlib, pandas
Format:
.pkl,.pngModel metadata is described using elements of the FAIR4ML schema(e.g. software environment, training parameters, target variable).
All code used to train and evaluate the model is version-controlled and publically available on GitHub.
{kind=link}