Illicit antiques trade network knowledge graph

Description
1. Dataset Description
Research Domain
This dataset was developed within the domain of digital humanities and criminology, specifically the study of illicit antiquities trafficking networks. It was created as part of the research outlined in the article: "Relationship Prediction in a Knowledge Graph Embedding Model of the Illicit Antiquities Trade" published in Advances in Archaeological Practice (Cambridge University Press).
Purpose
The dataset serves the purpose of transforming historical information about the Italian illicit antiquities trade into a machine learning-friendly knowledge graph format. and evaluating the performance of several embedding models on this dataset, as a way of exemplifying the usefulness of Knowledge Graphs in this domain.
This enables:
- Relationship prediction through knowledge graph embeddings.
- Exploration of networked criminal behavior through computational methods.
- Development of "digital tools" for combating illicit antiquities trading, responding to calls from funding bodies like the EU Horizon Europe scheme.
By producing this Notebook, I aim to support researchers and practitioners in better understanding and predicting the structure of hidden criminal networks.
Data Sources
The dataset is based on an 1995 "organigram" seized by the Carabinieri, depicting the network of antiquities traffickers. Supplementary information from the Trafficking Culture Project Encyclopedia (as of May 2022) has been added by the authors. The data reflects a bounded body of knowledge as curated by the Trafficking Culture Project and is not an exhaustive or final catalog of the trade.
Method of Dataset Creation
The original dataset was created through the following steps:
- Extraction of network data from historical sources and digital encyclopedic entries.
- Conversion into a knowledge graph where nodes represent individuals/entities and edges represent relationships.
Further it has been processed as such:
- Splitting the graph into training, validation, and testing datasets (80%/10%/10% split). A fixed random seed (42) was used throughout to ensure reproducibility.
- Mapping entity and relation IDs back to their labels for human interpretability.
- Used for training multiple knowledge graph embedding models (TransE, ComplEx, ConvE, DistMult) using PyKEEN pipelines.
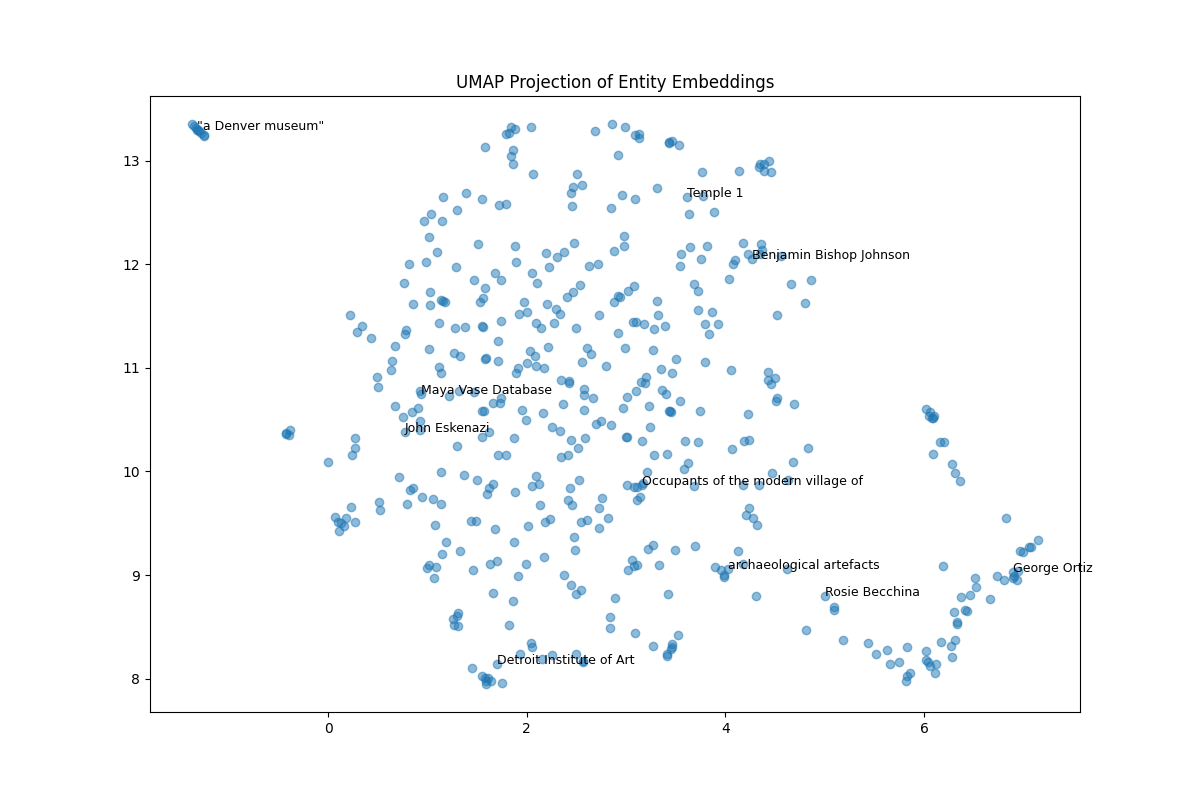
The best ranking model was further used for UMAP dimensionality reduction and Cosine similarity search between entities
The knowledge Graph was enriched with semi-automatically generated Labels using the spaCy library.
2. Technical Details
Dataset Structure
The original dataset is organized into a single .CSV file with columns: head — the subject entity, relationship — the predicate (relation type), tail — the object entity. Each row represents a triple in the knowledge graph.
An additional column, split, indicates membership in "train," "validation," or "test" subsets.
Naming Conventions
Columns are labeled with descriptive names.
Entity and relation labels have been mapped back from their original integer IDs to human-readable names.
Dataset splits are explicitly labeled (train, validation, test).
Measurement results and trained models are saved under suggestive names in dedicated folders
Images and Figures are saved as .JPG in a dedicated folder. These include
- A histogram visualizes the distribution of different relationship types across the dataset.
- A spring layout graph, where edges between entities are color-coded based on their relationship type.
- Bar plots vizualising how the embedding models scored in certain relevant metrics
Required Software
The dataset is provided as a Pandas DataFrame or can be exported as a CSV.
Requires Python libraries such as:
- pandas
- numpy
- torch (for tensor manipulations)
- spaCy
- PyKEEN library for knowledge graph embedding modeling. The latest stable version of Python that supports PyKEEN is 3.9 (according to PyKEEN documentation)
Additional Resources
Original Research Article: https://doi.org/10.1017/aap.2023.1
Trafficking Culture Encyclopedia: https://traffickingculture.org/encyclopedia/
PyKEEN Documentation: https://pykeen.readthedocs.io/en/stable
3. Further Details
Data Limitations:
The source material is historically bounded and non-exhaustive. There may be bias based on the original focus areas of the Trafficking Culture Project. While based on public historical documents and research, users should exercise caution if trying to infer sensitive or personally identifiable information.
Licensing and Attribution:
Appropriate credit should be given to the original authors and the Trafficking Culture Project, as the data is under ... license.
Recommended Uses:
- Academic research into illicit trade networks.
- Development and testing of knowledge graph embedding models.
- Exploratory work on machine learning approaches to organized crime network analysis.
Known Issues:
Some relationships in the original data are inferred or reconstructed based on available evidence, rather than direct observation.
Model performance may vary based on sparsity and the nature of the network structure.
Active and passive voice do not reflect in the directionality of the relationships.
Files
generated_labels.csv
Files
(14.5 MiB)
| Name | Size | |
|---|---|---|
|
md5:e8c302f066b4c92a69895db1a3fe7022
|
888.9 KiB | Download |
|
md5:a96ec78c6907dd96333c68cf4f874ba8
|
93.3 KiB | Download |
|
md5:628caa7ef3cc2546580409d6a1dc4037
|
13.0 KiB | Preview Download |
|
md5:66d076399b0da20f703916a2b1b62278
|
63.2 KiB | Preview Download |
|
md5:5abfacd2892fd36404d835bc2178e115
|
27.7 KiB | Preview Download |
|
md5:e60f4ddd353b068b2450a843c19a18cf
|
3.6 MiB | Preview Download |
|
md5:df605191cc80c8d8b850b13647fcd70e
|
270.2 KiB | Preview Download |
|
md5:f1d7eeac8df67c3e9f408db51738ba1f
|
111.2 KiB | Download |
|
md5:db75a4378f576d167e1ebd33f82253af
|
875.2 KiB | Download |
|
md5:79756aac9b2cb8c432dc8808fcad870a
|
8.4 MiB | Download |
|
md5:182f39fe94fdb049a2b96e9c3f759421
|
111.8 KiB | Download |
|
md5:c67837c2431abf384025749cf3a2341b
|
3.6 KiB | Preview Download |
|
md5:1fee653cf9b2b526c2978ad0548eaaa8
|
3.1 KiB | Preview Download |
|
md5:65d7942202097ff29936994399afb8d1
|
12.0 KiB | Preview Download |
|
md5:38202dbf4ed7cfe6785f7f2da85a5a86
|
12.3 KiB | Preview Download |
|
md5:28dbe01aa419b00d9536824b9f1db185
|
12.3 KiB | Preview Download |
|
md5:480a8dbefcfca1816052c81c26b67463
|
11.9 KiB | Preview Download |
|
md5:66fbb53ec98362d5607cdaabb95a7c9b
|
28.7 KiB | Preview Download |
|
md5:43774cdd7346f9b82d6ac890341dc95d
|
337 Bytes | Preview Download |
|
md5:73cc454da3e1d78125190ef41723219e
|
3.9 KiB | Download |
|
md5:23a14d3df04ed5cc62196ab3e5c257db
|
84.0 KiB | Preview Download |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Additional details
Related works
- Cites
- Journal Article: 10.1017/aap.2023.1 (DOI)
- Is source of
- Dataset: 10.82556/xfvk-2712 (DOI)